Outrageous Info About How To Check Duplicates In A Table
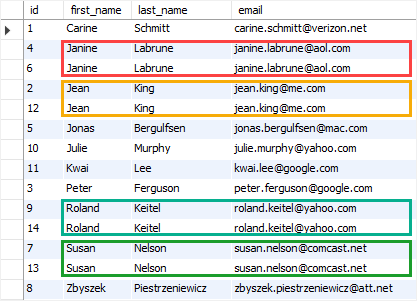
How To Find Duplicate Values In Mysql

How To Find Duplicate Records In Table Sql - Youtube

Sql Server - How Can I Find Duplicate Entries And Delete The Oldest Ones In Sql? Stack Overflow

How To Find Duplicate Records That Meet Certain Conditions In Sql? - Geeksforgeeks
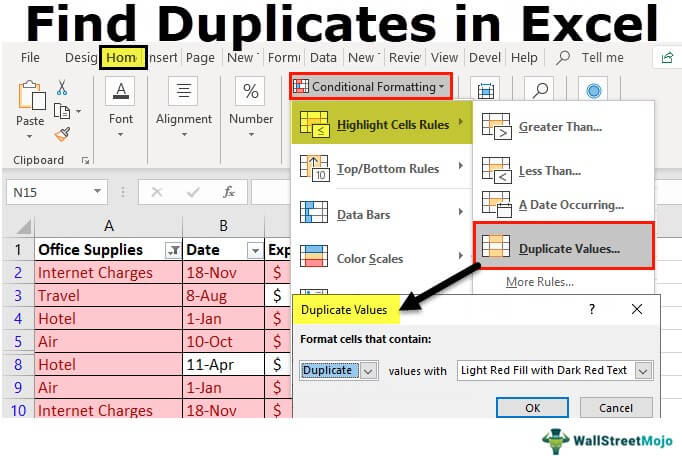
Find Duplicates In Excel - How To Identify/show Duplicates?

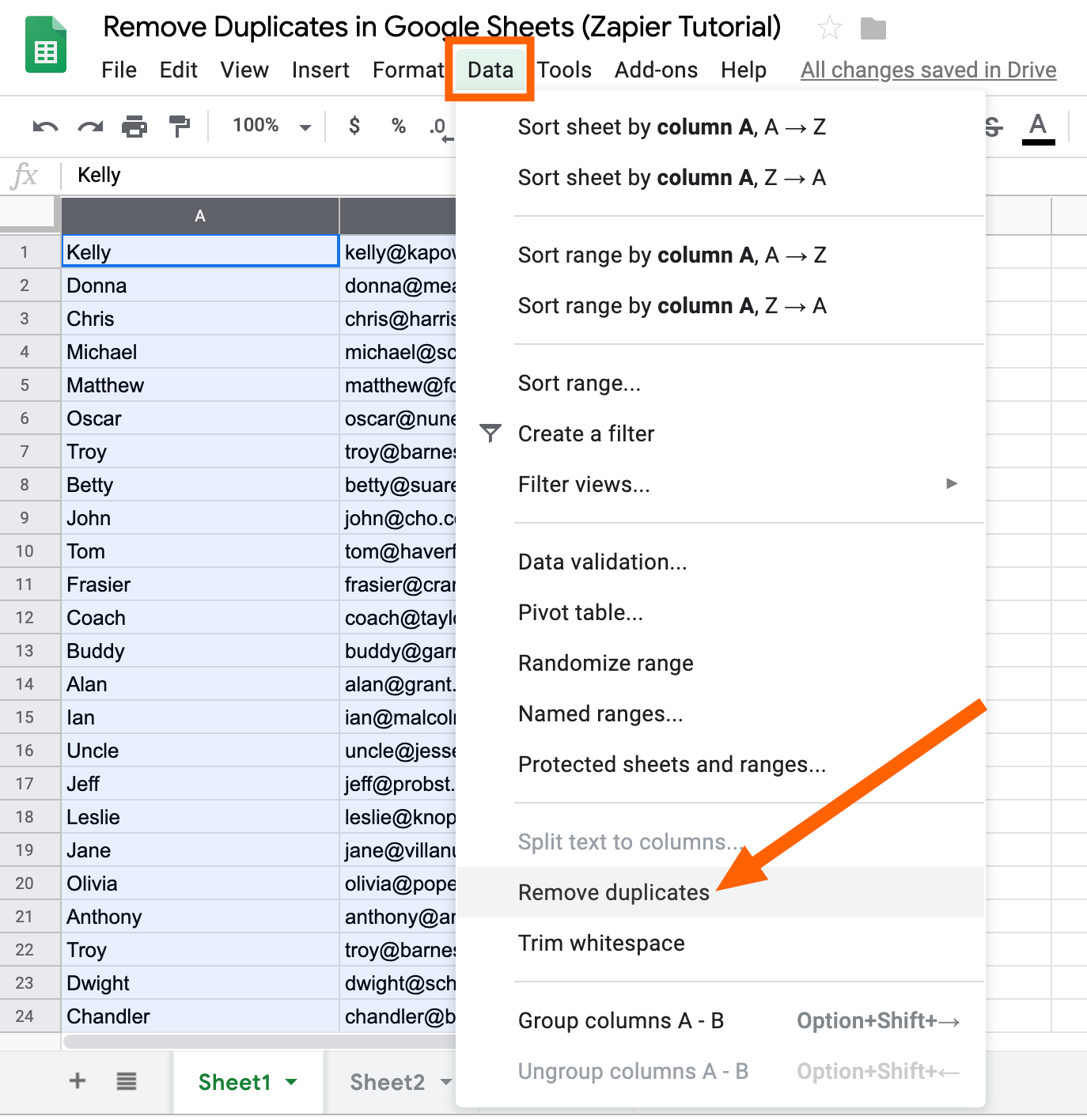
How To Find And Remove Duplicates In Google Sheets
First, use the group by clause to group all rows by the target column, which is the column that you want to.
How to check duplicates in a table. You have to use different methods to identify and delete duplicate rows from hive table. Use intermediate and snowflake distinct keyword. You can find duplicates by grouping rows, using the count aggregate function, and specifying a having clause with which to filter rows.
Consider u r first field of itab consists of duplicate values. Use the select count statement to find the number of occurrence of duplicates in a mysql table. Loginask is here to help you access what causes duplicates when.
This is one of the easiest methods to remove the duplicate records from the table. In this query, we added an over () clause after the count. @qbss lets consider your table as, dttable first try getting all the duplicate rows, dtduplicatetable = dttable.asenumerable().groupby(function(dr) dr.field(of.
The find duplicate values in on one column of a table, you use follow these steps: At first, you need to define the criteria for finding the duplicate names. Select f.*, count (*) over ( partition by fruit_name, color) c from fruits f;
To find the duplicate names in the table, we have to follow these steps: Nov 01, 2007 at 10:36 am. Below are some of the methods that you can use.
Now, after detecting the existence of duplicates, we can use the select count. Select name, category, from product. With cte as ( select col , row_number() over ( partition by col.


How To Find Duplicate Records That Meet Certain Conditions In Sql? - Geeksforgeeks
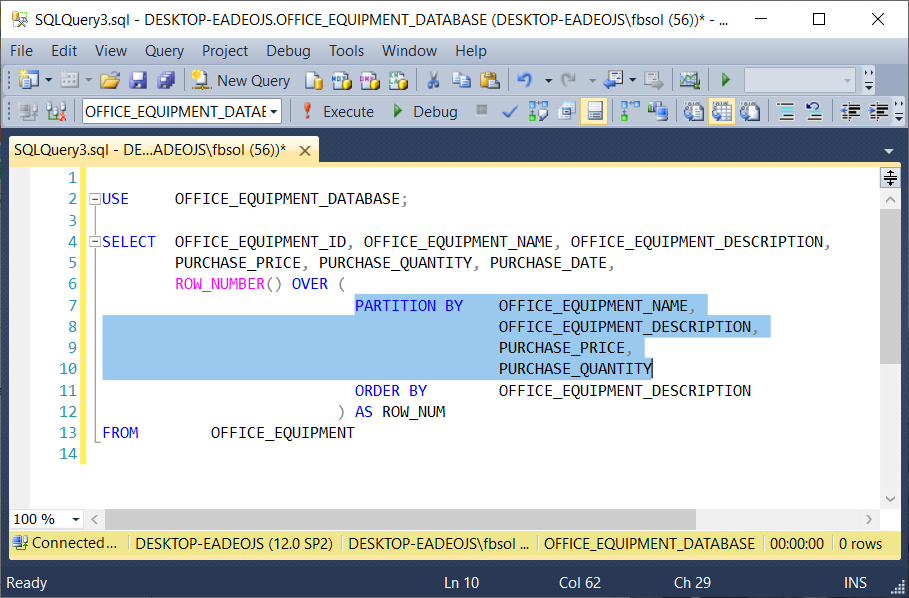
Lever T-sql To Handle Duplicate Rows In Sql Server Database Tables

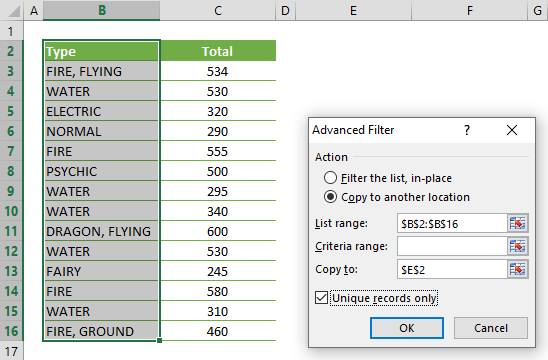
Pivot Table: Table Show Duplicates | Exceljet
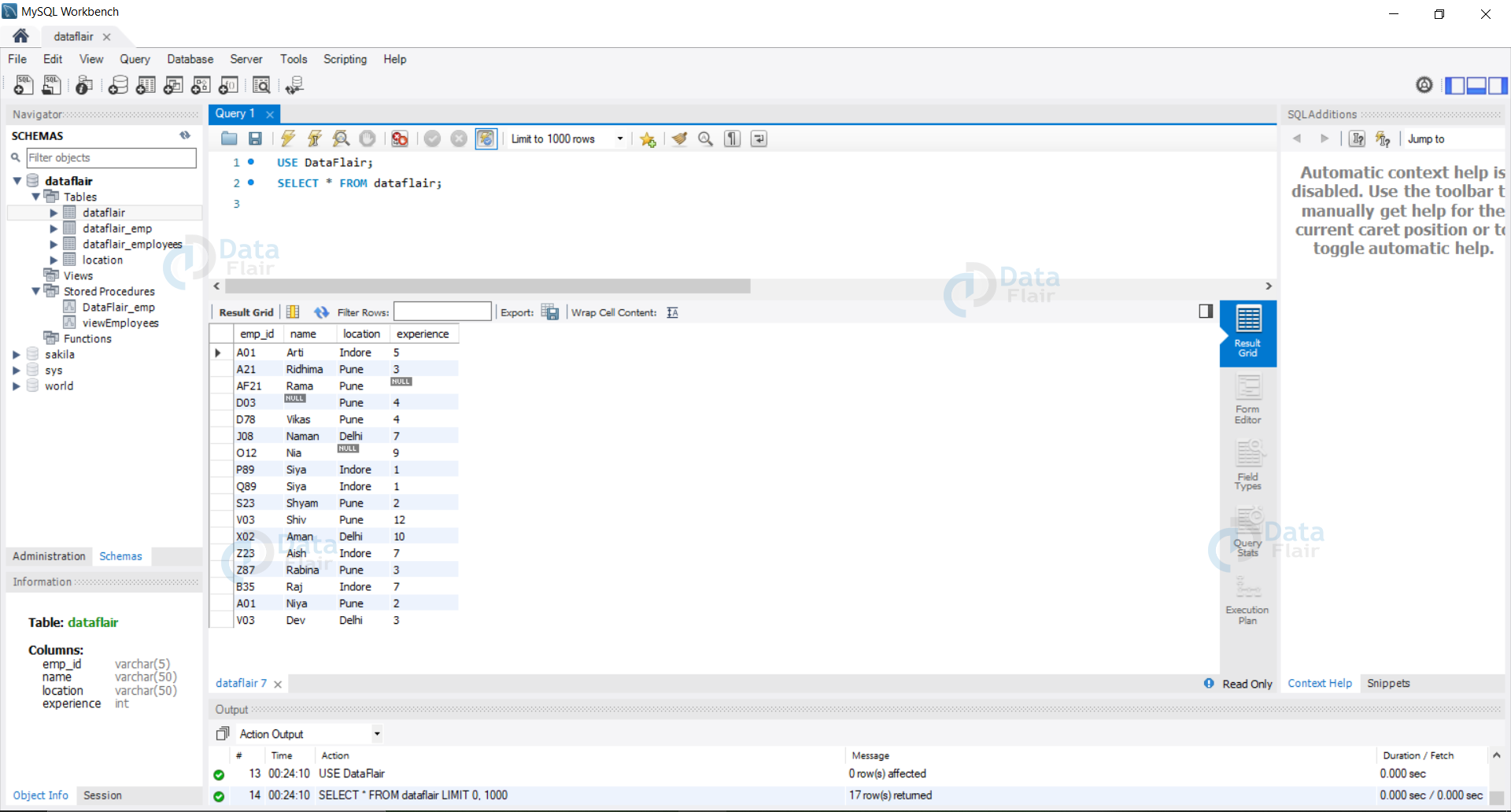
How To Find Duplicate Records In Sql - With & Without Distinct Keyword Dataflair
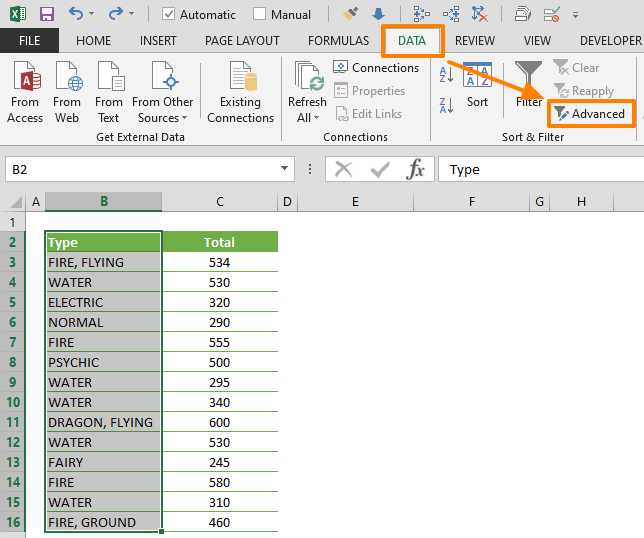
How To Find Duplicates In Excel And Remove Or Consolidate Them
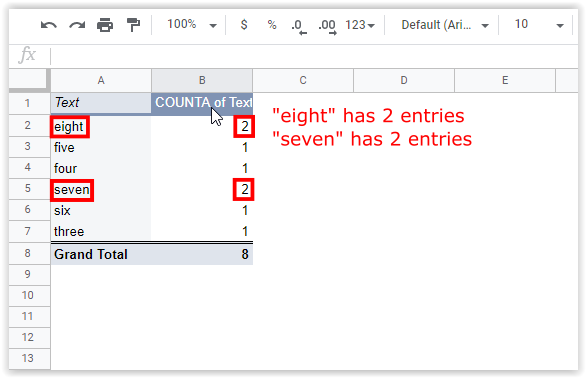
How To Find And Remove Duplicates In Google Sheets
How To Find Duplicates In Excel And Remove Or Consolidate Them
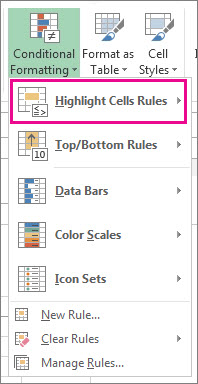
Find And Remove Duplicates
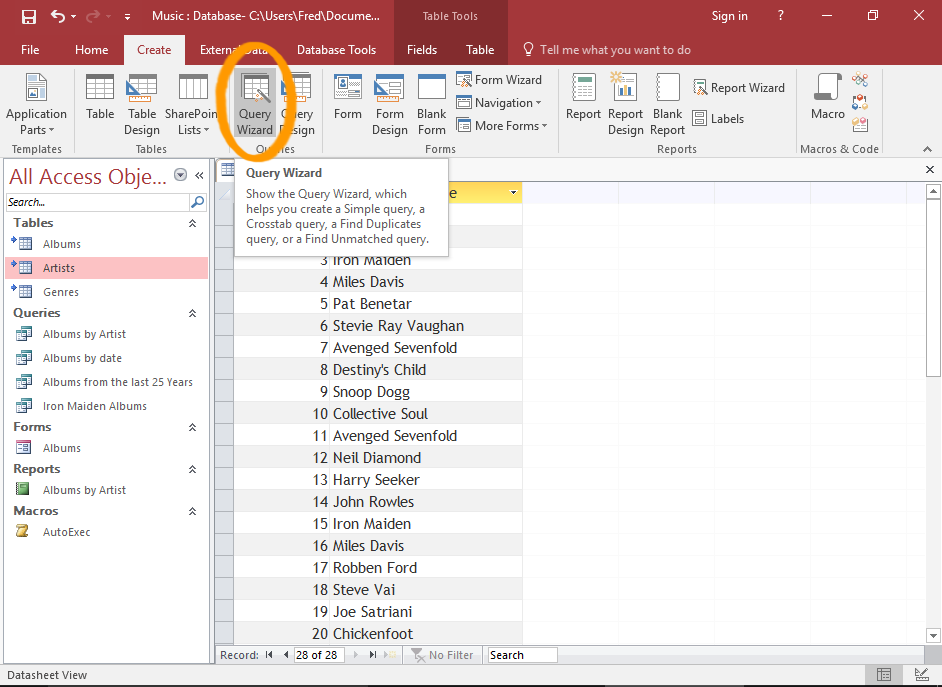
How To Find Duplicate Records In Access
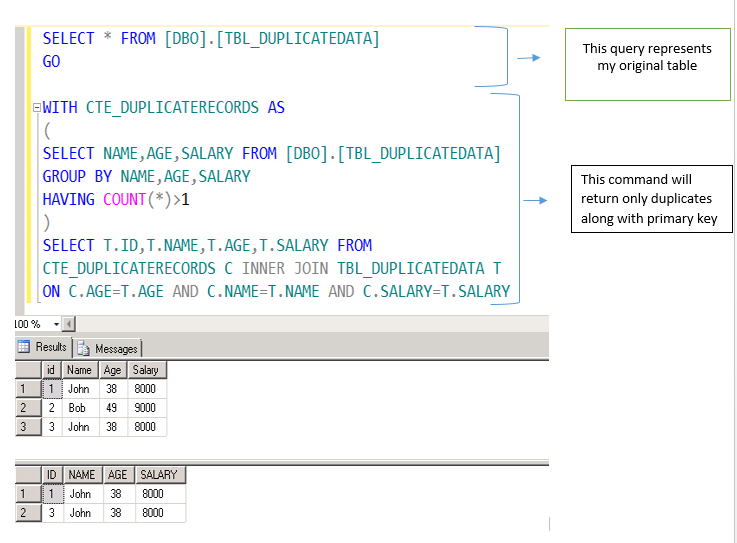
Select Only Duplicate Records In Sql Server - Training
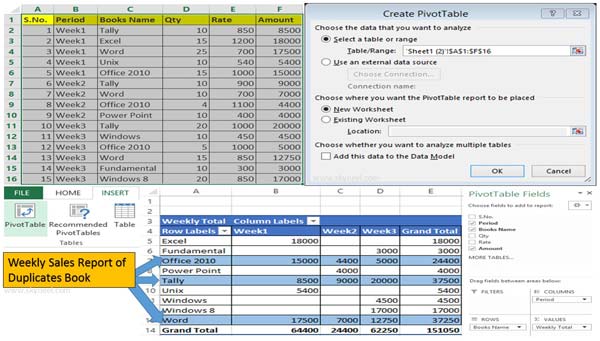
How To Find Duplicates With Pivot Table In Excel
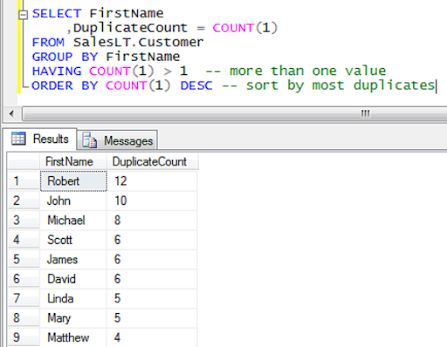
Javarevisited: How To Find Duplicate Values In A Table? Sql Group By And Having Example| Leetcode Solution